

Indexing API jest interfejsem pozwalającym na powiadomienie Google o zmianach związanych z adresami URL w danym serwisie internetowym. Do takich zmian należą:
- dodanie adresu URL do indeksu Google;
- aktualizacja adresu URL (technicznie przeindeksowanie);
- usunięcie adresu URL z indeksu Google;
- uzyskanie statusu ostatniego żądania.
Indexing API nie służy do indeksacji!
Pomimo swojej nazwy – Indexing API nie odpowiada za dodawanie adresu URL do indeksu.
Zgodnie z dokumentacją – mowa tutaj o crawlowaniu, a nie indeksowaniu.
Request index (tak nazywa się wysłanie informacji do Google) odpowiada za natychmiastowe przecrawlowanie/zeskanowanie adresu URL, które na poniższym wykresie widnieje pod nazwą Crawler.
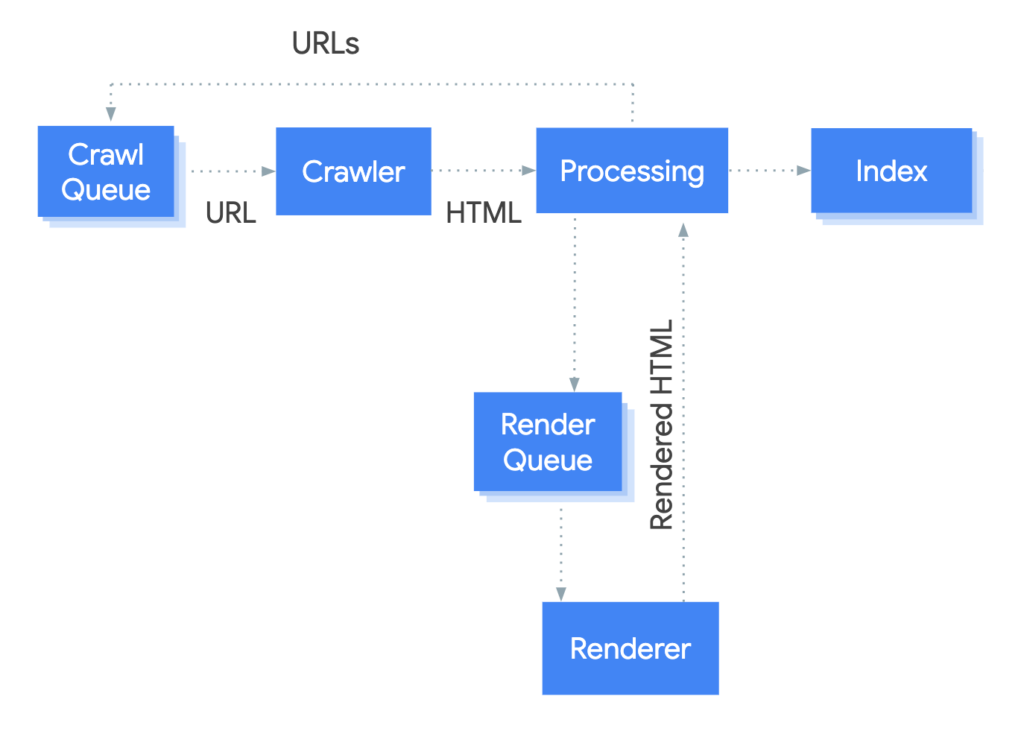
W przypadku Request Index pomijana jest kolejka crawlowania, więc po zeskanowaniu danego adresu URL Googlebot przechodzi do jego przetwarzania (na wykresie Processing). Po tym procesie (trwającym średnio od 4 do 6 godzin, a czasem nawet i 24 godziny) Google podejmuje decyzję, czy chce dodać dany adres URL do indeksu.
Googlebot może również podjąć decyzję o nieindeksowaniu danego adresu, jeżeli nie spełni on określonych wymagań, które to nasz specjalista Sebastian Heymann określił mianem MVI – Minimum Value to Index, czyli minimalna wartość do zindeksowania.
Indexing API Request to natychmiastowe skanowanie adresu URL i przejście do jego przetwarzania, a nie jak się powszechnie określa „dodanie adresu URL do indeksu”.
Mimo widniejącej w dokumentacji wzmianki, że jest to zaplanowanie crawlowania dla stron, w naszych testach na tysiącach przypadków potwierdzono, że działanie jest niemalże natychmiastowe. Maksymalne opóźnienie, jakie uzyskaliśmy przy skanowaniu, wyniosło kilkanaście sekund.
Minimum Value to Index
Minimum Value to Index (w skrócie MVI) to teza (teoria potwierdzona testami, które ujawnimy niebawem), która mówi, ile reputacji musi „zdobyć” dany adres URL, aby został dodany do indeksu.
Reputację tę podzielono na czynniki on-site oraz off-site.
Do czynników on-URL należą wszystkie elementy indeksujące się pod danym adresem URL, mianowicie:
- menu i stopka serwisu;
- główna treść serwisu;
- inne indeksowane treści (informacje o ciasteczkach, formularze, alty obrazów);
- czynniki Page Experience, takie jak:
- Core Web Vitals;
- HTTPS;
- mobilność;
- brak reklam przeszkadzających przeglądanie serwisu;
- czas reakcji adresu URL -> Time to First Byte (TTFB).
Do czynników off-URL należą wszystkie elementy niezwiązane bezpośrednio z próbą indeksowania określonego adresu URL, mianowicie:
- linki zewnętrzne;
- linki wewnętrzne;
- zduplikowane adresy URL w obrębie serwisu;
- zduplikowane adresy URL poza serwisem;
- wartość domeny.
Gdy dany adres URL otrzyma odpowiednią wartość na podstawie powyższych czynników, Google doda taki adres do indeksu.
Jeżeli zdarzyło Ci się wysłać Request Index już kilkukrotnie, a ciągle nie został on zindeksowany, szukaj przyczyn w czynnikach wskazanych powyżej.
Zalety i wady Indexing API
ZALETY |
Ominięcie kolejki crawlowania |
Realizacja w czasie rzeczywistym |
Nie wpływa na crawl budget serwisu |
Działa nie tylko dla JobPosting i Broadcast Event |
Przyśpieszenie prac nad SEO serwisu |
Najszybszy sposób indeksowania stron |
WADY |
Tylko 200 requestów dziennie per project na Google Cloud |
Maksymalnie 100 requestów ciągiem |
Limit dzienny według czasu amerykańskiego GMT-4 |
Osobny interfejs |
Tylko dla zweryfikowanych domen w GSC |
Indexing API nie tylko dla JobPosting i Broadcast Event
Pomimo tego, iż w dokumentacji widnieją informacje o tym, że narzędzie przeznaczone jest tylko dla ofert pracy oraz stron z audycjami video, działa ono również dla innych typów podstron. John Mueller na swoim Twitterze poinformował, że Indexing APi działa wyłącznie dla JobPosting i Broadcast Event, a każdy inny rodzaj treści będzie ignorowany.
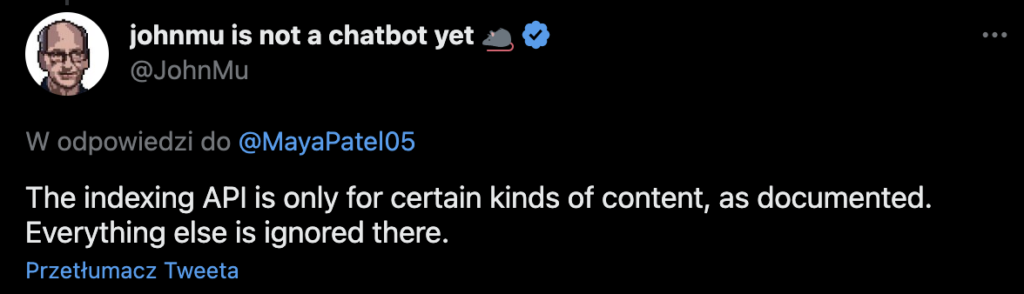
John Mueller został również zapytany o to, co się wydarzy, jeżeli spróbuje się wykorzystać Indexing API do innego typu treści. Odpowiedział on, że w takich sytuacjach rozwiązanie po prostu nie okaże się pomocne.

Na szczęście zapytano go również, czy jeżeli ktoś podejmie tego typu próbę, która zadziała, to czy można otrzymać za to karę? John odpowiedział, że NIE.

Dlaczego Indexing API działa dla innego rodzaju treści?
Odpowiedź wydaje się być dość prosta – Googlebot nie wie, co znajduje się na danej podstronie póki jej nie odwiedzi. Nie ma możliwości sprawdzenia, czy w kodzie HTML znajduje się JobPosting lub Broadcast Event, jeżeli wcześniej adres URL nie zostanie zeskanowany/przecrawlowany.
Mogłoby to mieć zastosowanie w przypadku usuwania adresów URL (ponieważ wcześniej taki adres musi być znany), ale również w takich przypadkach nasze testy wykazały, że z indeksu możemy usuwać adresy URL, których tematyka nie jest związana z wcześniej wspomnianymi treściami.
Uważamy, że interfejs jest nieco zastępstwem tego, co każdy użytkownik może zrobić w swoim Google Search Console klikając w „poproś o zindeksowanie adresu URL”. Nie trzeba jednak w tym przypadku uruchamiać interfejsu Google Search Console i wcześniej pobierać adresu, a co za tym idzie, zaoszczędzone zostaną zasoby Google.

Indexing API zamiast Request Indexing w Google Search Console
W Google Search Console możesz pobrać maksymalnie kilka adresów URL dziennie, w Indexing API aż 200.
Indexing API vs Sitemapa w XML
Poniżej w tabelce znajdziesz informacje, jakie są różnice między sitemapą, a Indexing API.
Indexing API |
Pewność zeskanowania adresu URL w czasie rzeczywistym |
Wiesz, kiedy URL zostanie zeskanowany |
Osobny interfejs |
Dane z requestów zawsze dostępne w Google Search Console |
Limit do 200 requestów dziennie |
Liczba requestów nie jest uzależniona od crawl budgetu |
Sitemap.xml |
Brak pewności zeskanowania adresu URL, nawet w przyszłości |
Nie wiesz, kiedy adres URL zostanie zeskanowany |
Możliwość dodania w Google Search Console lub pliku robots.txt |
Dane z requestów nie zawsze dostępne w Google Search Console |
Duże sitemapy zapewniają więcej niż 200 requestów dziennie |
Liczba requestów uzależniona od crawl budgetu |
Powyższe elementy są inaczej przetwarzane, dlatego pamiętaj o tym, korzystając z nich.
Zaplanuj dodawanie URLi do Indexing API i nie dodawaj ich na początku do sitemapy. To pozwoli Ci na bardziej optymalne crawlowanie nowych adresów URL.
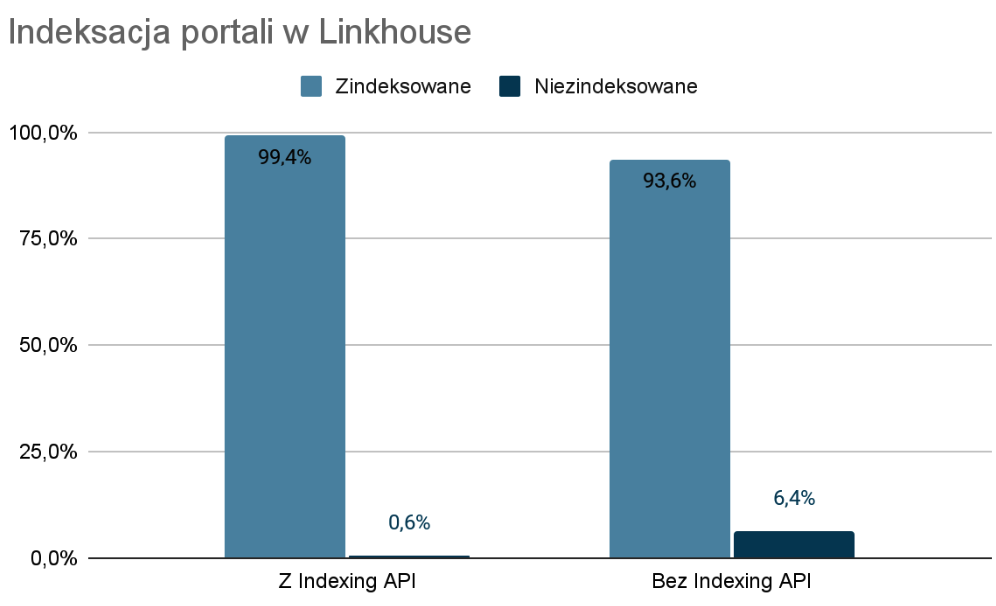
Portale z podpiętym Indexing API w Linkhouse
Poziom indeksacji portali z Indexing API wynosi niemalże 100%. Pojedyncze, niezindeksowane adresy URL wynikają z indeksacji innego adresu URL, niepoprawnego adresu URL lub chwilowych problemów z dostępem do serwisu wydawcy.
Wydawco – pamiętaj, że dla reklamodawcy najważniejsze jest, żeby indeksowały się kupowane przez niego publikacje.
Reklamodawco – pamiętaj, że możesz wybierać portale, które dodały się do aplikacji Indexing API od Google w Linkhouse, mając jednocześnie niemal 100% pewności, że Twój artykuł zostanie dodany do indeksu.
Indexing API – do czego?
Do czego można wykorzystać Indexing API oprócz crawlowania / indeksowania adresów URL?
Poniżej przedstawiono listę możliwości, które pozwolą Ci zrozumieć, dlaczego powinieneś jak najszybciej wspomagać swoje działania SEO poprzez Indexing API.
Przeindeksowanie treści
W sytuacji, kiedy pracujesz nad treścią, optymalizujesz ją, zmieniasz lub część nieaktualnej treści usuwasz, dla przyspieszenia szybkości jej przeindeksowania możesz wysłać Request Index do tego URLa i cieszyć się przeindeksowaniem zdecydowanie szybciej.
Nie musisz czekać na zeskanowanie URLa znajdującego się w kolejce crawlowania, bowiem nigdy nie wiadomo, kiedy dany adres zostanie przeskanowany.
Pamiętaj, że przeindeksowanie wiąże się z MDR, czyli Minimum Difference to Reindex. W przypadku wykonania zbyt małych zmian (poprawa literówek, korekta szyku zdania, dodanie zdjęcia) Google może uznać, że nie warto przeindeksowywać adresu URL.
Usunięcie adresu URL z indeksu
Dzięki Indexing API możesz usunąć nieaktualne adresy URL z indeksu za pomocą URL_deleted lub za pomocą URL_updated.
- URL_deleted zastosuj w przypadku, gdy usunąłeś dany adres URL i nic już się na nim nie znajduje (zwraca kod HTTP 404).
- URL_updated zastosuj do usuwania z indeksu, gdy adres URL istnieje, ale nie chcesz żeby znajdował się w indeksie Google, a w nagłówku <head> zaznaczyłeś informację o jego nieindeksowaniu za pomocą meta robots=noindex, ale zwraca kod HTTP 200.
Szybsza weryfikacja problemów krytycznych z Google Search Console
Widząc strony niezindeksowane w Google Search Console, wielu specjalistów korzysta z przycisku „sprawdź poprawkę”, która następnie jest odrzucana, ponieważ nie naprawiono wszystkich adresów URL znajdujących się w raporcie, a tylko ich część. Jeżeli nie skorygowano wszystkich adresów, dodaj te adresy URL do indexing API, zamiast korzystać z przycisku „sprawdź poprawkę”. Krytyczne problemy, którymi warto się zająć to m.in.:
- błąd serwera;
- błąd przekierowania;
- duplikat, użytkownik nie oznaczył strony kanonicznej.
Przyśpieszenie crawlowania URLi
Widzisz sporo adresów URL w raporcie: „strona wykryta – obecnie niezindeksowana”? To sytuacja, w której dany adres URL znajduję się w kolejce do crawlowania, ale nie został jeszcze zeskanowany przez Google. To dzięki Indexing API możesz przyśpieszyć crawlowanie tych adresów i nie przejmować się tym, że prawdopodobnie znajdują się daleko w kolejce. Widzisz tam strategiczne z punktu widzenia Twojego biznesu adresy? Do dzieła!
Narzędzia do Indexing API
Jeżeli powyższy artykuł przekonał Cię do skorzystania z Indexing API, to możesz taką aplikację zaimplementować na swoim desktopie. Gotowe kody i instrukcję znajdziesz w poniższych linkach
- https://github.com/m3m3nto/giaa (Memento from Rome)
- https://github.com/marekfoltanski/indexingapi (Marek from Poland)
DLA PL: Możesz również skorzystać ze stworzonego już systemu przez Rolanda Adamczyka – seograjek.pl lub zaimplementować aplikację od TopOnline.pl.
Badanie: Czy Indexing API wpływa na Crawl Budget?
Badanie 1
Dane wejściowe:
- stabilny serwis ze stałą liczbą crawlowania stron z kodem HTTP 200;
- kilkadziesiąt requestów dziennie dla tych samych adresów w poszczególne dni;
- pobieram tylko te adresy, które były w indeksie.
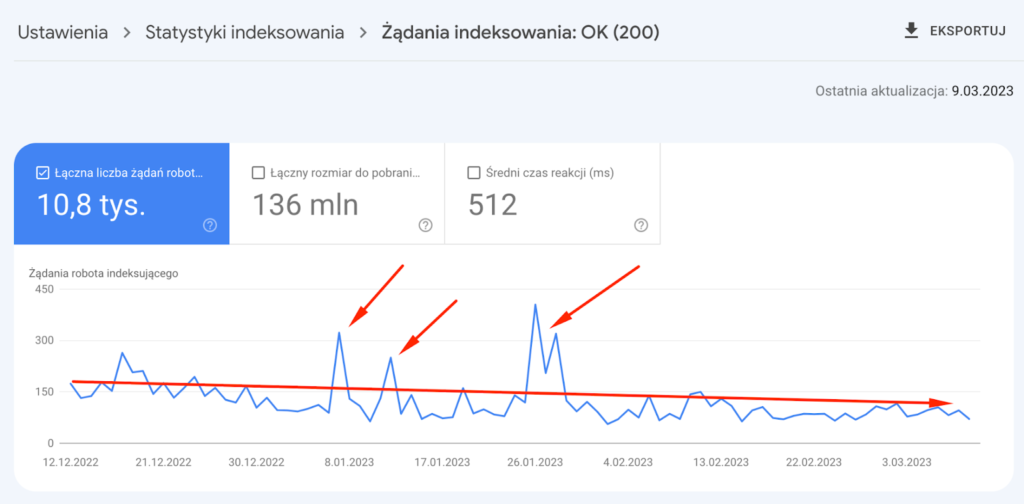
Linia trendu skanowania była nieco spadkowa.
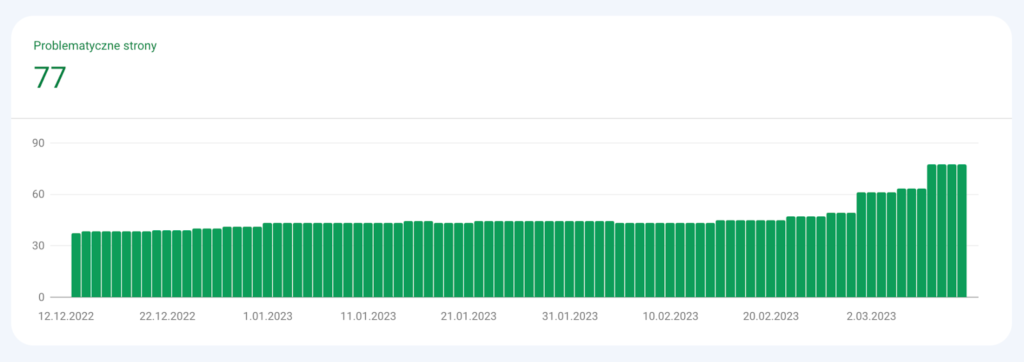
Liczba zindeksowanych adresów URL znajduje się na stałym poziomie.
Wynik: brak pozytywnego lub negatywnego wpływu Indexing API na crawl budget serwisu. Wygląda na to, że Indexing API to tylko dodatek do bieżącego Crawl Budgetu.
Badanie 2
Dane wejściowe:
- stabilny serwis ze stałą liczbą crawlowania stron z kodem HTTP 200;
- requesty dla adresów URL, które już zwracają 404;
- pobieram tylko te adresy, które są w indeksie Google.
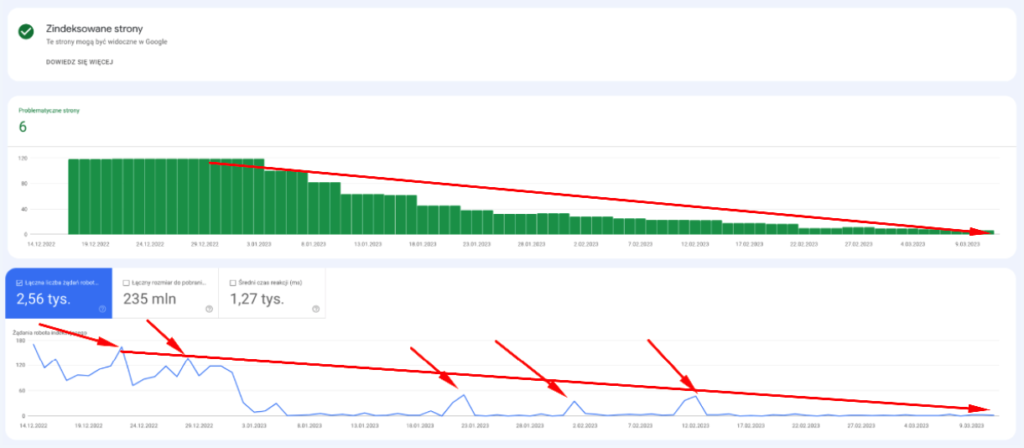
Wynik: spadek crawlowania nie wynika z requestów Indexing API, a z powodu liczby adresów URL w indeksie.
Badanie 3
Dane wejściowe:
- stabilny serwis ze stałą ilością crawlowania stron z kodem HTTP 200;
- requesty tylko dla adresów URL, które zawierają kod HTTP 200;
- requesty dla adresów URL, które wcześniej były w indeksie oraz tych, których w nim nie było.
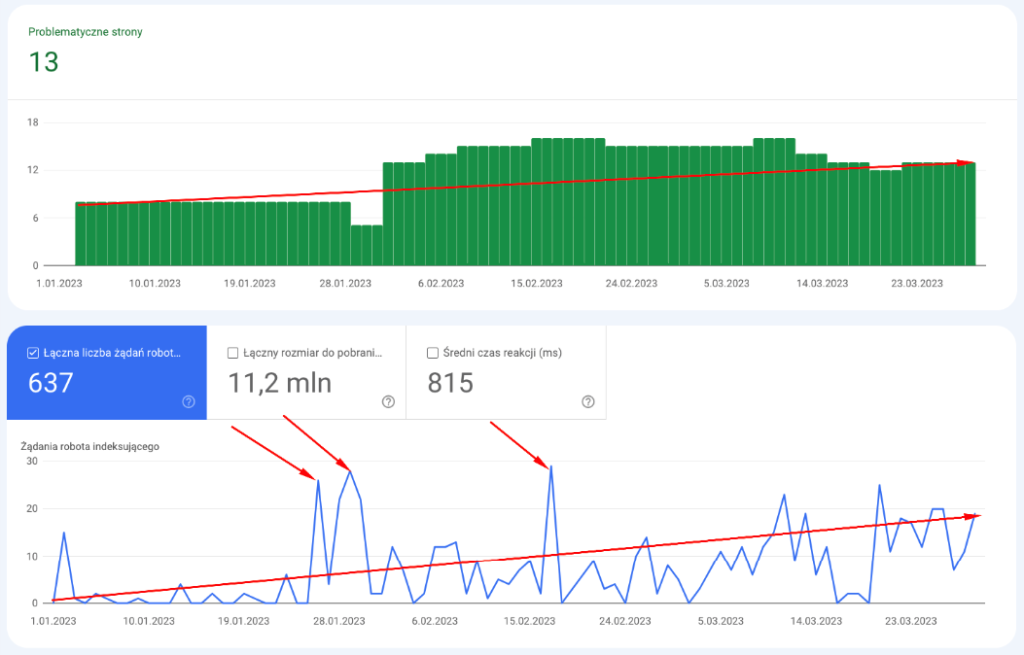
Wynik: po trzech sesjach w Indexing API i zaindeksowaniu nowych adresów URL, wzrósł średni Crawl Budget serwisu.
Wnioski
- Indexing API wyciąga adresy URL z kolejki crawlowania;
- Indexing API nie wykorzystuje bieżącego Crawl Budgetu witryny;
- Samo crawlowanie przez Indexing API nie powoduje zwiększenia ani zmniejszania Crawl Budgetu;
- Crawl Budget zależy od liczby adresów URL w indeksie;
- Indexing API może pośrednio wpływać na Crawl Budget, poprzez:
- dodanie / usunięcie adresów URL z indeksu;
- wyciąganie adresów URL z kolejki crawlowania.
Jak ominąć limit 200 requestów na dzień?
Limit wynoszący 200 requestów na dzień, dotyczy jednego projektu na jeden adres e-mail. Jeżeli utworzysz 10 projektów, to możesz skorzystać z 2000 requestów dziennie – w taki sposób możesz rozszerzać pulę wyjściową.
Pamiętaj, że musisz być zweryfikowanym właścicielem danego serwisu w Google Search Console, aby na innym koncie Google również wysyłać requesty do tego samego serwisu.
Podsumowując – Indexing API to Crawling API
Jak wspomniano wcześniej – Indexing API to tak naprawdę Crawling API z możliwością usuwania adresów URL z indeksu oraz pobierania informacji bieżących o adresach URL. Adres zostanie zindeksowany dopiero wtedy, kiedy osiągnie odpowiedni poziom wartości do indeksacji (Minimum Value to Index). Zachęcamy do korzystania z Indexing API, póki takie rozwiązanie działa wobec każdego adresu URL – jeśli, zgodnie z pierwotnym założeniem, zacznie ono działać wyłącznie dla JobPosting oraz Broadcast Event, niestety będzie konieczność korzystania z indekserów.

Autor
Sebastian Heymann – SEO w jego życiu istnieje od 2011 roku. Człowiek od trudnych pytań i do trudnych pytań. Współtwórca narzędzia Link Planner. Twórca jedynego szkolenia SEO z wykorzystania Google Search Console. Uwielbia podważać, kwestionować, testować oraz kreować publiczne debaty. SEO i analiza danych to jego pasje, którymi uwielbia się dzielić z innymi.




